AI Аналитика. Пример отчёта по событию
Подробно рассмотрим пример отчёта по сквозной аналитике в личном кабинете Андата.
Отчёт Андата — сквозная аналитика
В Андата появился новый готовый отчет Сквозная аналитика, доступный для всех пользователей аналитики Андата. Расскажем, как выглядит этот отчет, из каких анных формируется и в чем его основные особенности.
В отчете могут быть визуализированы любые события на пользовательском пути, которые отслеживает трекинг-код Андата.
Это могут быть события сайта или других интегрированных систем, например, можно вывести в отчет события из вашей CRM, ERP системы, колл-трекинга, и так далее.
В отчете применяется 4 модели атрибуции, между которыми можно переключаться — данные пересчитываются на лету.
Давайте рассмотрим подробнее основные блоки отчета.
В верхней части отчета расположен фильтр по источникам в виде значений UTM-меток.
Ниже — количество событий, по которому построен отчет, а также количество переходов и паспортов, задействованных в отчете. В нашем примере в качестве примера использовано событие оплаты.
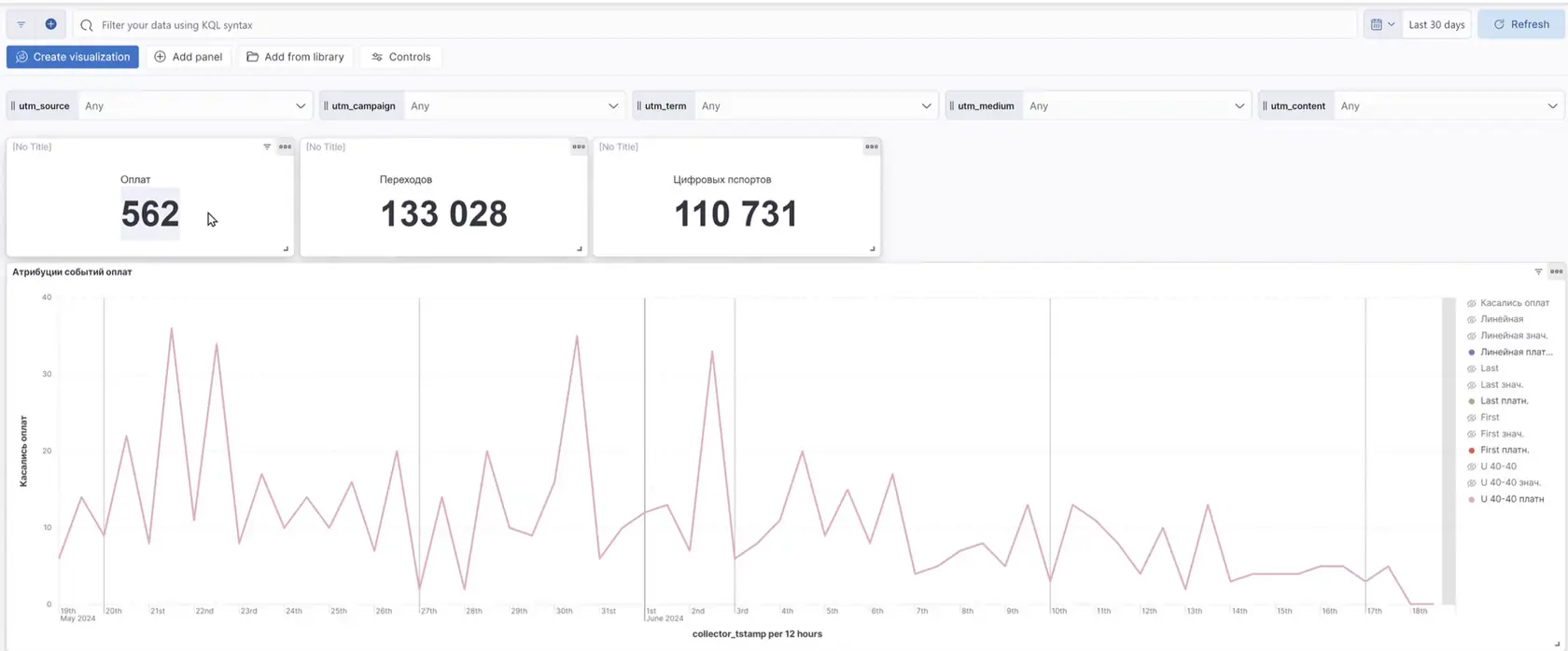
👆🏻На графике представлены оплаты с применением различных моделей атрибуции, визуализированные по времени.
Давайте рассмотрим, какие модели атрибуции есть в Андате и как они будут влиять на график Оплат в привязке к выбранному каналу.
Модели атрибуции
Всего в Андата есть возможность использовать 13 разных моделей атрибуции. Мы остановимся на 4 наиболее популярных: линейная модель, first click, last click и U-shape.
Линейная модель
Учитывает все внешние каналы, предшествующие событию, и считает их одинаково ценными.
First click и last click
Присваивают заслугу за конверсию первому или последнему взаимодействию пользователя с рекламой перед покупкой соответственно.
Например, пользователь сначала кликнул на рекламу в рекламной сети Яндекса, а потом совершил покупку через несколько дней после просмотра других рекламных объявлений ВКонтакте. Заслуга за эту покупку будет приписана РСЯ в первом случае и ВК во втором.
U-shape модель
Присваивает 40% доходов или штуки от единицы конверсий первому каналу, ещё 40% — последнему каналу, а оставшиеся 20% распределяет между всеми остальными каналами, которые были между первым и последним.
Например, пользователь сначала кликнул на рекламу в Одноклассниках, затем на рекламу в Яндексе, а потом на рекламу ВКонтакте, после чего совершил покупку. В модели U-образной атрибуции: 40% — ОК (первое взаимодействие), 40% — ВК (последнее взаимодействие), 20% — между Яндексом и любыми другими промежуточными взаимодействиями.
Визуализация и анализ данных
Теперь поговорим о специфике этих моделей подробнее. Фильтруем каналы по Яндексу.
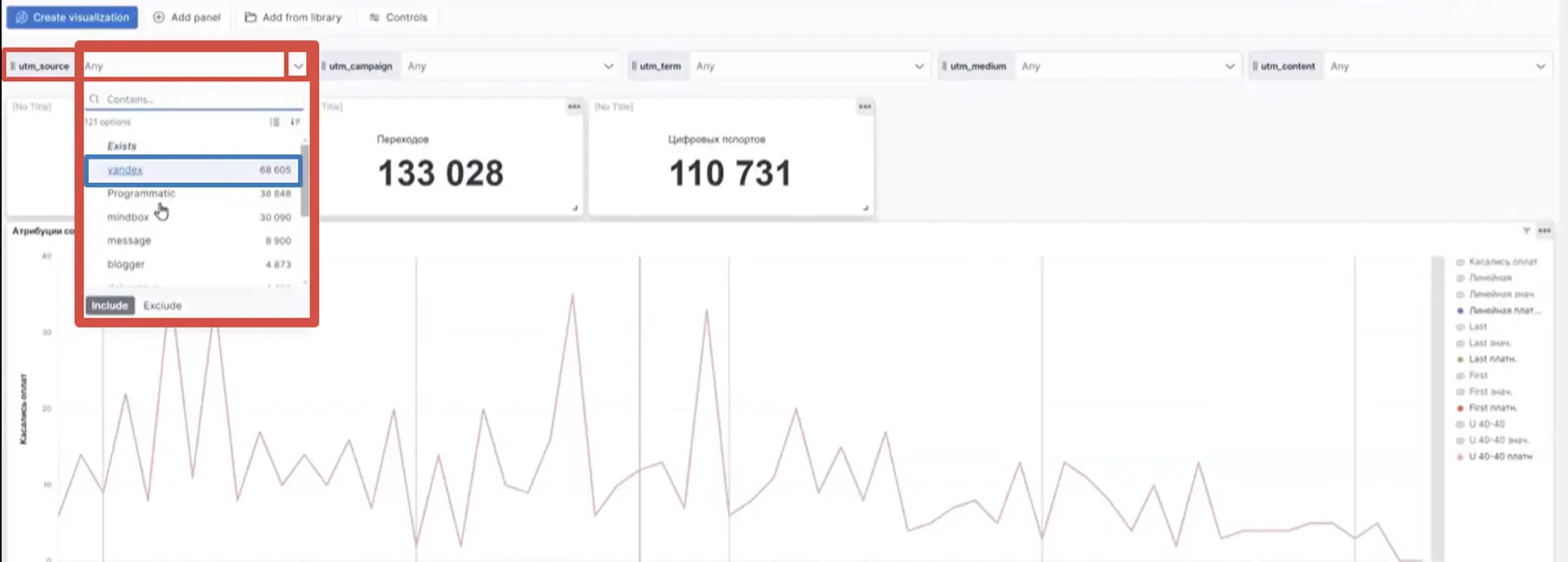
👆🏻 Для этого в поле «utm_source» открываем список каналов и выбираем «yandex».
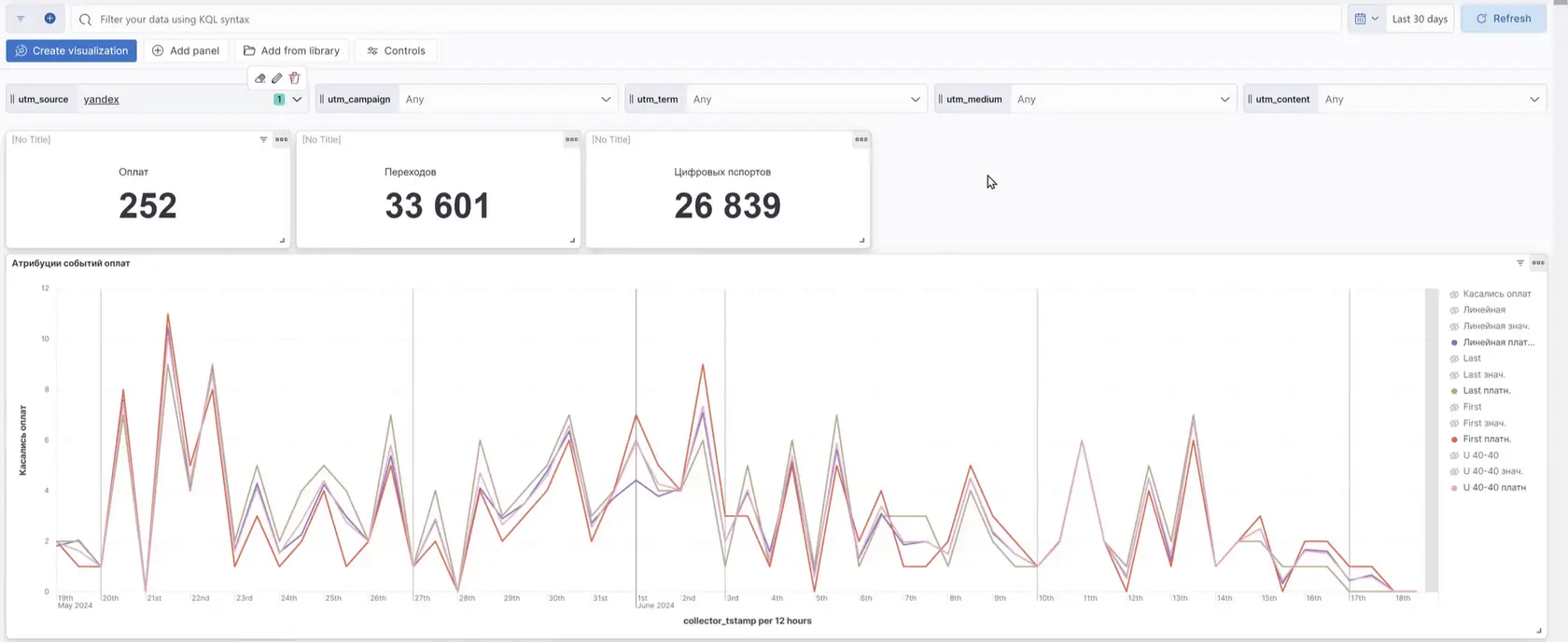
👆🏻На графике видим, как точки наблюдения, то есть сама модель атрибуции, влияют на результат.
Теперь мы оцениваем эффективность Яндекса — влияние одной модели атрибуции отличается от другой примерно на 30%. Это означает, что угол обзора изменяет цифры, по которым мы измеряем эффективность маркетинга.
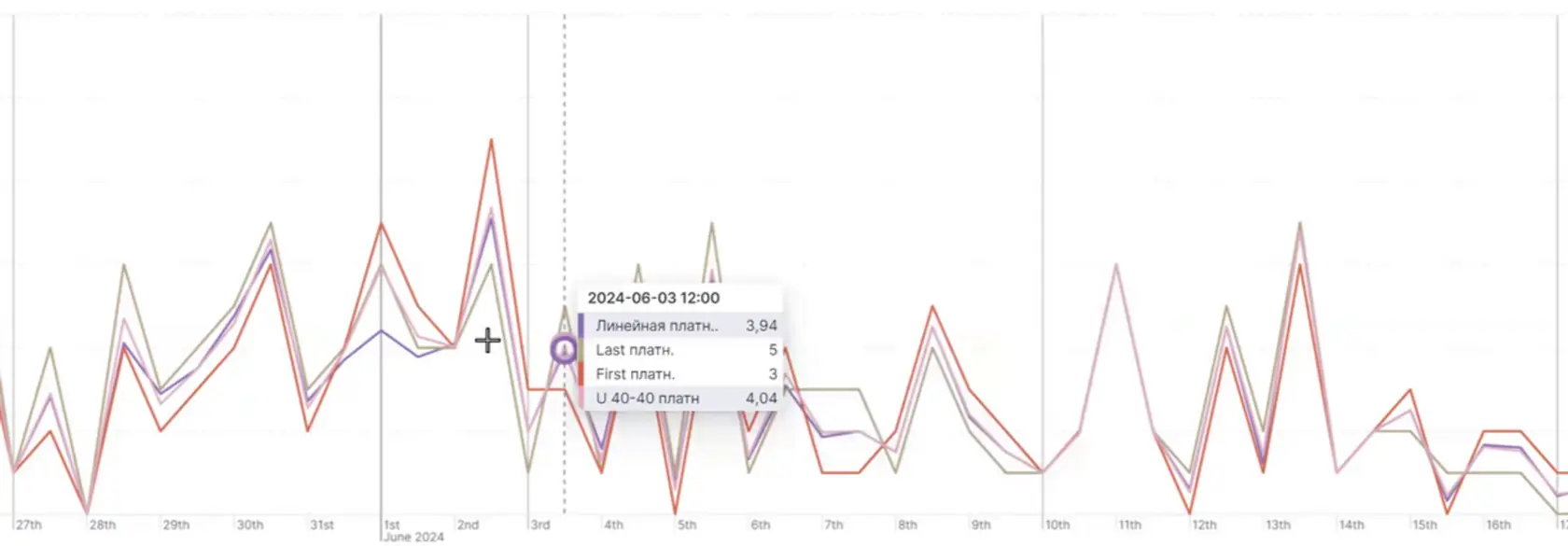
👆🏻 В отдельной точке на шкале видны значения для каждой модели с датой и временем.
Здесь используем 4 модели атрибуции, по каждой из которых есть разбивка на категории.
Распределяем заслугу между:
- платными — внешние каналы закупленного трафика, без прямого входа и без учёта органики,
- значимыми — органический трафик,
- всеми, когда учитываются только прямые входы.
👆🏻 Выбираем нужную модель из списка справа от графика.
Здесь визуализируем как отдельные элементы, так и доходы. Если события имеют доход, мы автоматически считаем их и распределяем по атрибуциям.
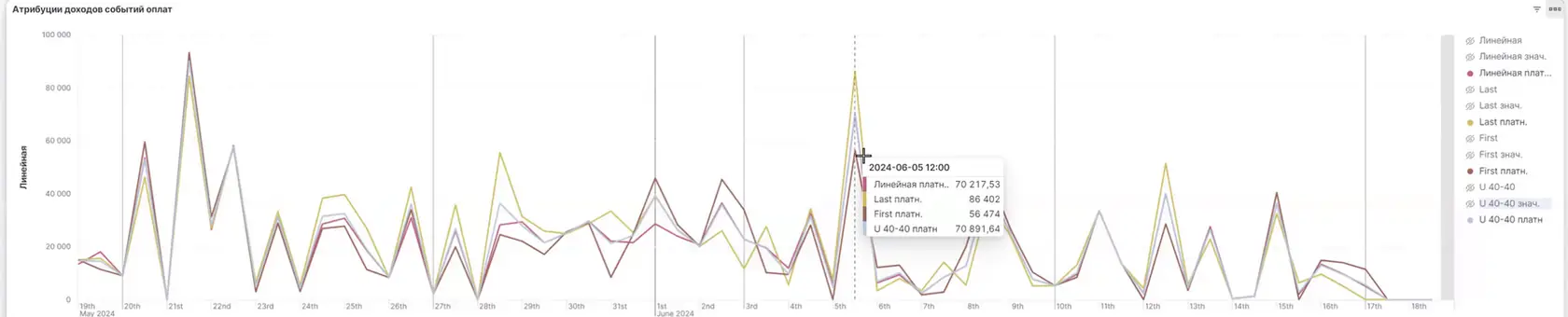
👆🏻 Смотрим суммы дохода по каждой модели в определённый момент времени.
Визуализация по всем источникам трафика
Чтобы посмотреть все каналы, количество трафика, который они привлекли, и уникальных пользователей, которые перешли с этих каналов, переходим к исходному формату.

👆🏻 Чтобы увидеть список всех каналов в одной таблице, нужно отключить фильтрацию только по одному каналу.
Для этого снова переходим к полю «utm_source», открываем всплывающее окошко с настройками фильтрации и кликаем по изображению урны, чтобы очистить фильтр. Затем переходим к отчёту «Атрибуции доходов событий оплат».
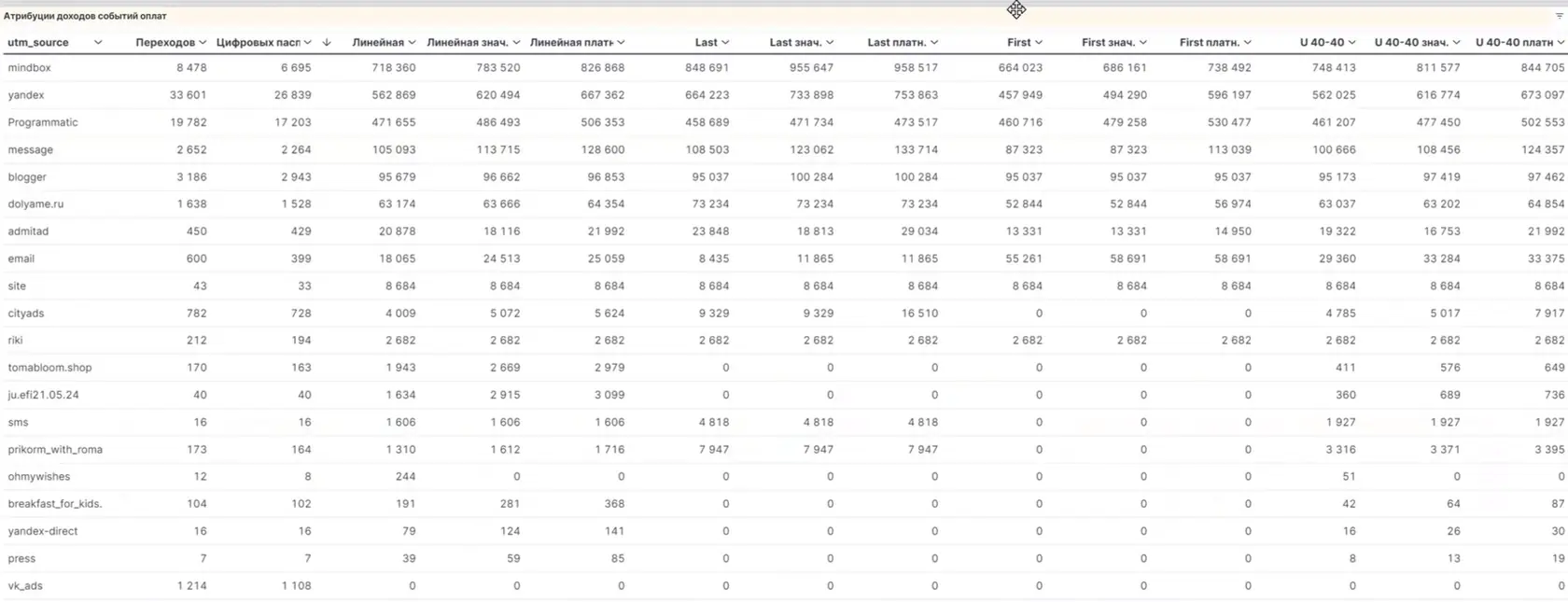
👆🏻 В исходном формате рассматриваем все каналы трафика в виде таблицы со значениями в суммах дохода по каждой модели атрибуции.
По каждой модели смотрим, сколько доходов принесли каналы и как именно работает атрибуция.
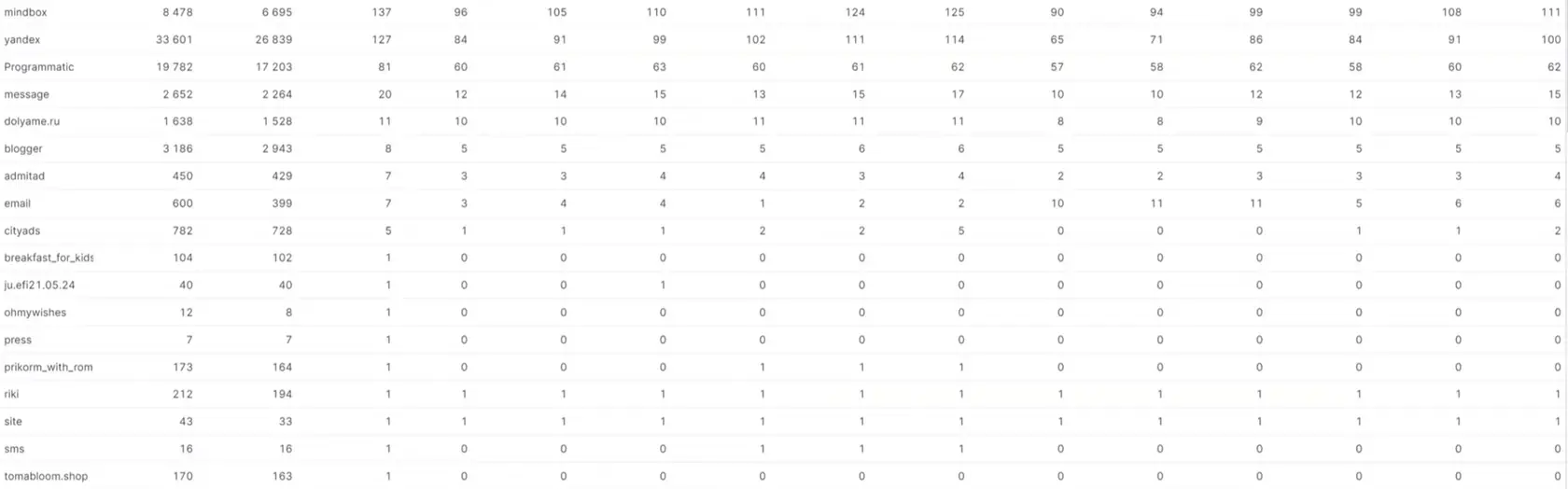
👆🏻Посмотреть сводную информацию о различных моделях атрибуции их значениях в штуках можно в дублирующейся таблице.
Например, если мы посмотрим на источник трафика MindBox, то увидим, что по равномерной модели доход составил 718 000, в значимых каналах — 783 520, т. к. таких каналов меньше, заслуга канала оценивается выше, а в платных каналах, которых ещё меньше, доход на конкретный стрим — 826 000.
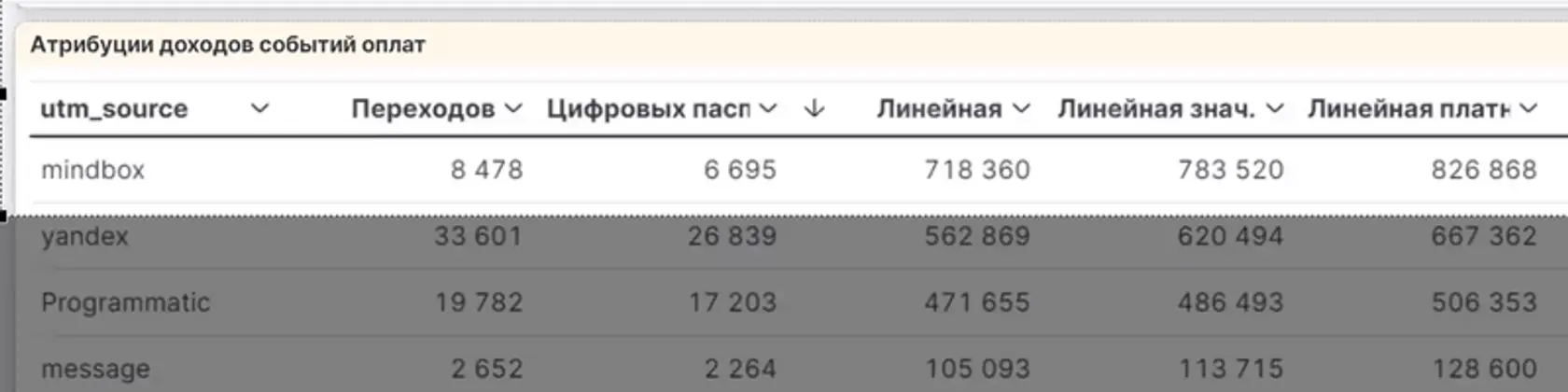
👆🏻 Смотрим цифры по отдельному каналу размещения рекламных объявлений и баннеров.
Анализ маркетинговых метрик по шаблону
Чтобы увидеть маркетинговый расклад, скроллим страницу ниже и переходим к отчёту “Сводка шаблон, дата клика”, в котором можно увидеть визуализации по шаблону, в которой отображаются:
- клики с каналов,
- уникальные пользователи,
- заслуги по избранной модели атрибуции,
- переходы в целевые действия,
- суммы доходов, сообщенных из размеченных событий,
- средний чек,
- доля доходов из размещения.
При наличии расходов можно посчитать ДРР и ROMI.

👆🏻 Таблица показывает отдельные маркетинговые метрики.
Группировка и классификация каналов
Дальше идёт визуализация, в которой можно использовать собственные классификации, чтобы отследить трафик в определённой группировке. Для этого объединяем разные рекламные кампании или каналы в отдельную таблицу — отчёт «Сводка справочник кампания-классификация», который содержит данные, которые настраиваются под отдельные нужды.
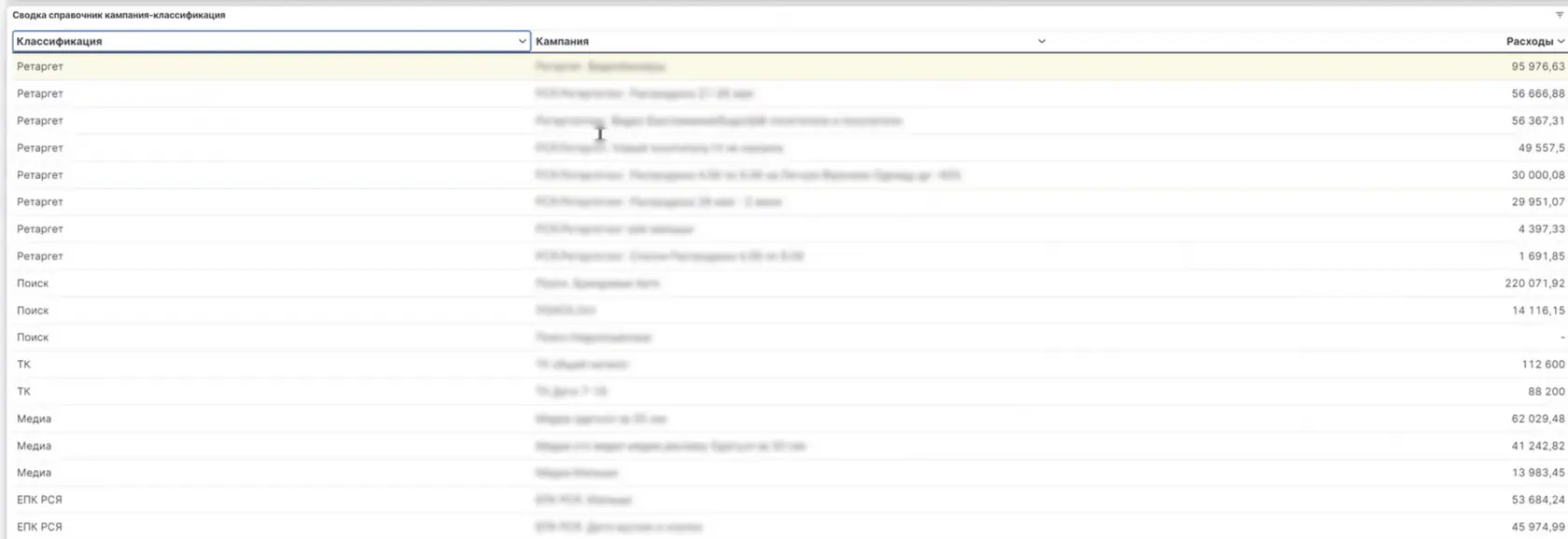
👆🏻 Группируем избранные каналы в отдельную визуализацию.
Например, некоторые рекламные категории внутри Яндекса можно разделить по потокам: РСЯ, ЕПК, ретаргетинг и товарные кампании. По этим категориям смотрим квоту по расходам и доходам, а также такие метрики, как ROMI и ДРР.
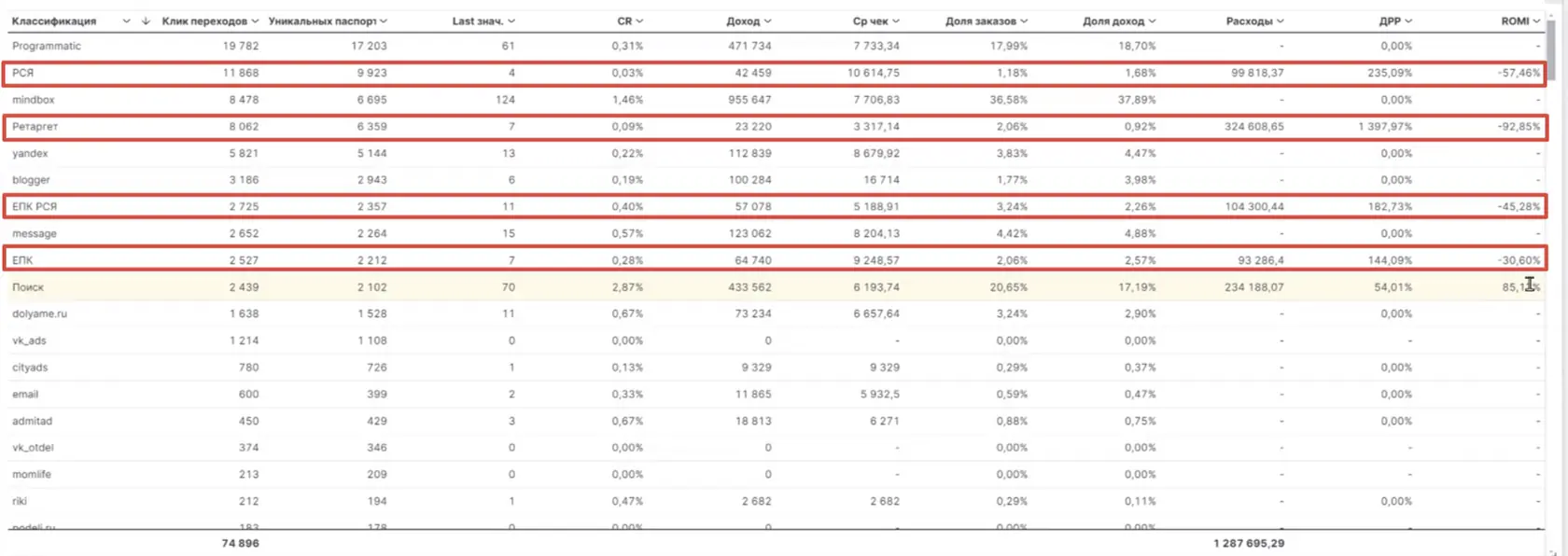
👆🏻 Классификация по отдельным категориям РК в Яндексе.
Когортный анализ и детализация
Один из наиболее интересных инструментов — визуализация по когортам. В этой визуализации мы видим информацию, связанную с датой привлечения трафика.
Это настраиваемый отчёт, который можно формировать в соответствии с заданными параметрами. В качестве примера мы рассмотрим отчёт о событиях оплаты, связанных с рекламными объявлениями в Яндексе.
Визуализация находится внизу списка таблиц — скроллим страницу вниз и выбираем отчёт «Недельная когорта utm-source = “yandex” по доходам» . Здесь выбираем уровень детализации данных: неделя, месяц или день. Дату можно выбирать произвольно.
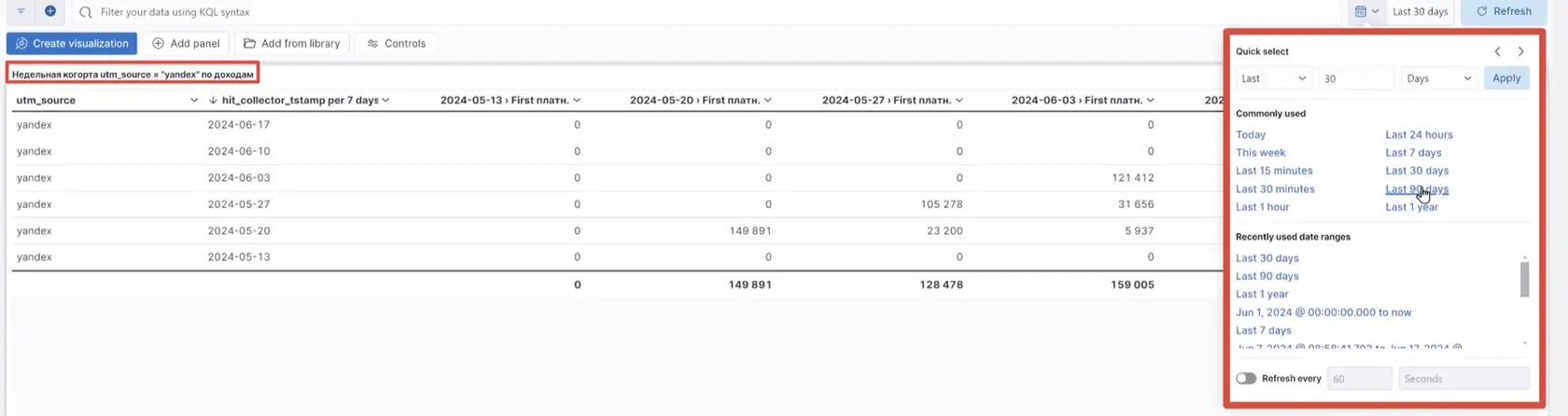
В меню настройки отчёта в слева от названия отчёта можно выбрать указать период учёта данных, сделать это можно 2-мя способами: выбрать из предложенных или указать самостоятельно в окне настройки визуализации.
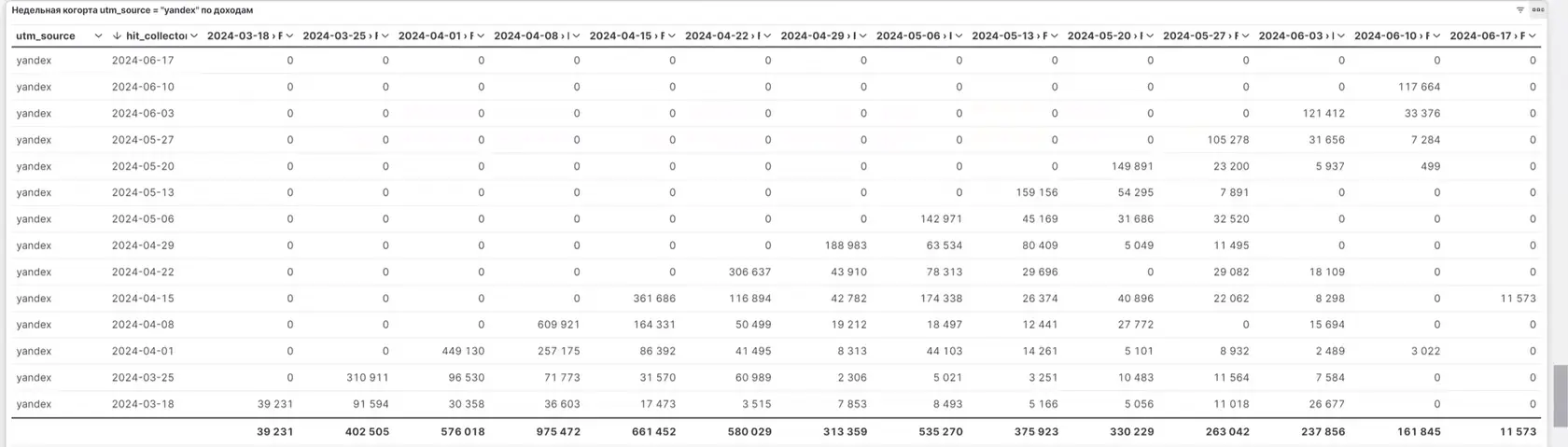
👆🏻 Когортный анализ по дате привлечения по неделям.
Например, если мы выберем недельный уровень детализации, то сможем увидеть информацию о дате, когда во внутренней CRM-системе происходила оплата с доходами.
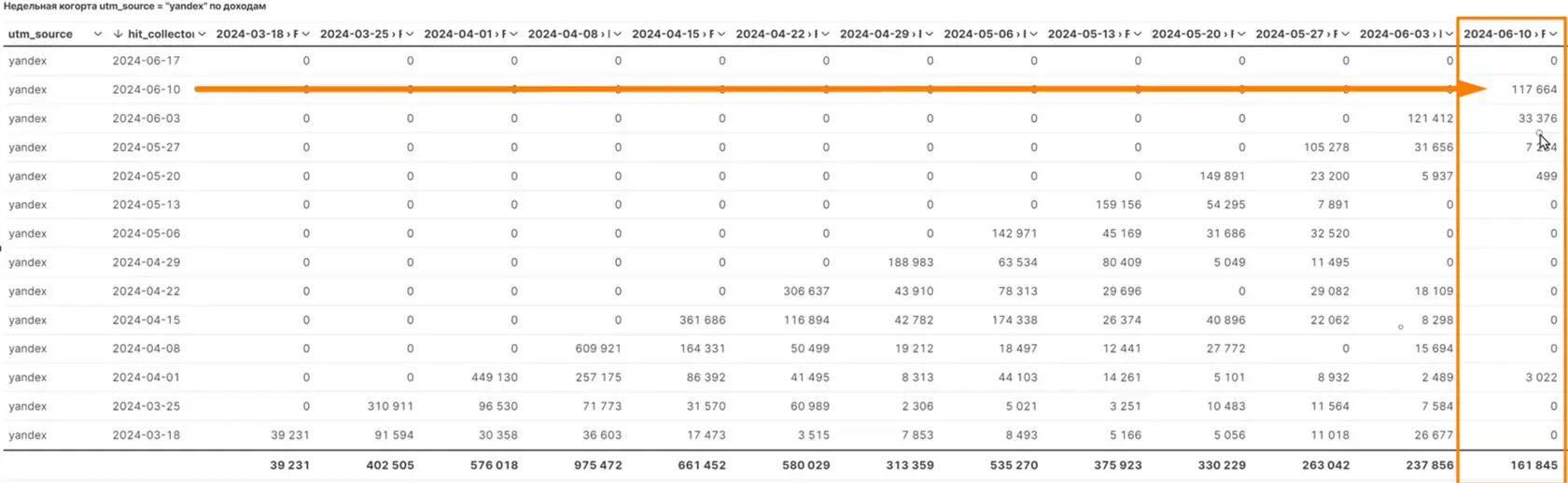
👆🏻В этой визуализации мы видим доход за неделю — 161 845. Эта сумма складывается из разных недель по привлечению в прошлом трафика, которые повлияли на этот доход.
Когорта, которую мы анализируем, — это доход за прошедшую неделю, а также трафик, который был привлечён за этот период. Он составляет 70% от общей суммы. Остальные 30% — это доходы от трафика, приобретённого ранее.
Цель такой когорты — определить конкретное свойство и время, которые привлекают аудиторию, которая надолго остаётся с нами, возвращается и продолжает делать покупки, не теряя интереса.
Подобные когорты можно создавать даже внутри Яндекса, например, разделять пользователей по типу устройства, версии операционной системы или бренду смартфона, например, последний iPhone или бюджетный Android.Так мы лучше понимаем характеристики каждого сегмента, их поведение и то, когда они обычно совершают оплату.
Для сегментации трафика в сервисе можно использовать разные подходы: разбивать трафик по признакам продукта (название, запросы, свойства), сегментировать по поведению пользователей (просмотренные страницы, страницы выхода) и экспериментировать с таргетингом и креативом.
В Андата автоматическая сегментация клиентской базы возможна при запуске оптимизации в один клик, при этом PPC-специалисты могут вносить правки вручную. Аудитория сегментируется по нескольким признакам, создавая кластеры целевых клиентов для каждой кампании. Точность сегментации обеспечивается нейросетевым алгоритмом, обучаемым на данных из цифрового паспорта пользователей. Сегментация зависит от тематики и особенностей бизнеса, например, по времени на сайте или микроконверсиям, если они настроены и проверены на наличие корреляции. Для создания такой
Таким образом, визуализации, которые мы рассмотрели и разобрали на отдельных примерах, показывают, какие отчёты можно создавать в личном кабинете Андата.
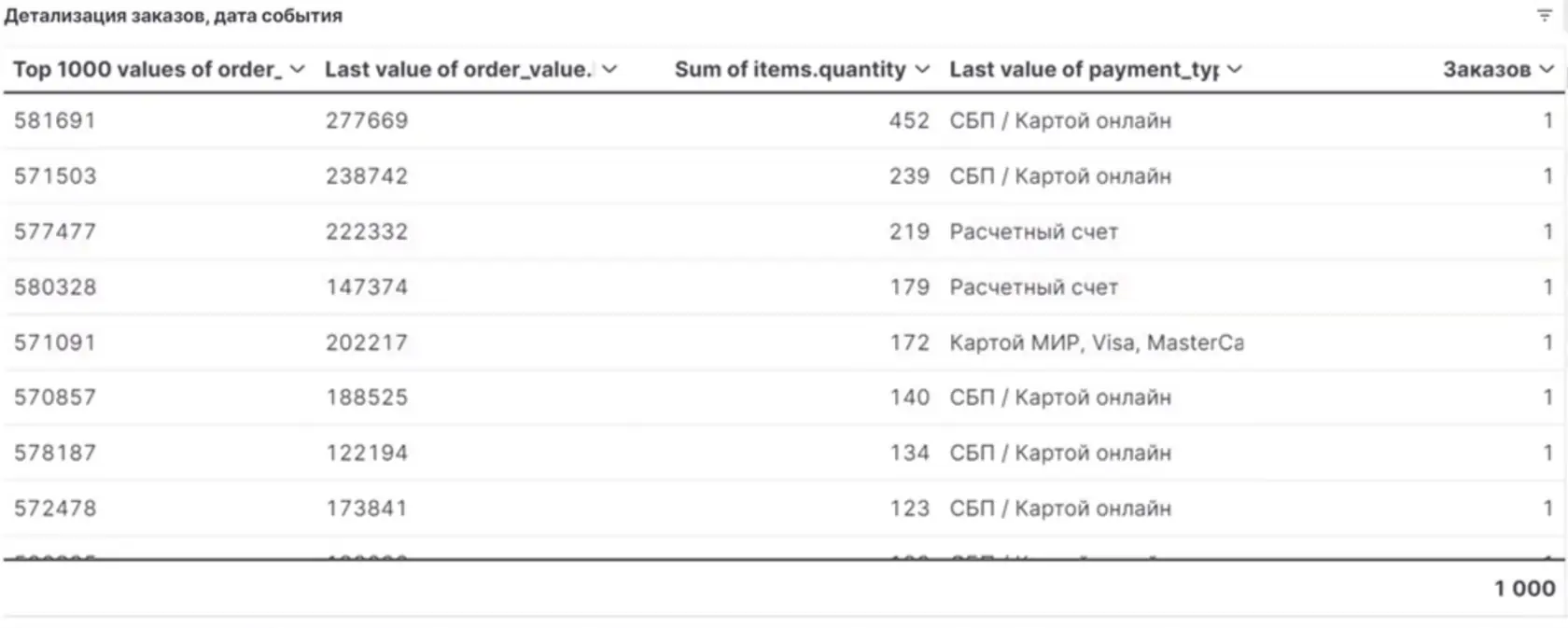
👆🏻Смотрим подробную детализацию по заказам, которые входили в пул, суммам дохода и средствам оплаты.
Детализация строится на данных, которые поступают от заказчиков через внутреннюю систему CRM. Если есть необходимые поля, подгружаем информацию о менеджере, который работал с клиентом, о специалисте, который проводил операцию, и так далее. Так мы можем проанализировать все эти данные и создать отчёты по различным критериям, включая каналы. За основу берём событие, которое, в свою очередь, связано со множеством предшествующих ему каналов. Для каждой единицы события можно создать подобные отчёты и наблюдать за показателями модели атрибуции.
Самое главное
Новый отчет по сквозной аналитике в Андате позволяет посмотреть на продажи под разным углом, применяя сразу несколько моделей атрибуции.
Благодаря этому можно определить маркетинговые каналы, которые:
- имеют наибольшее влияние на привлечение пользователей;
- влияют на принятие решения о покупке;
- вносят вклад в вовлечение и в возврат посетителей между первым привлечением и покупкой.
Вы сможете оценить реальное участие рекламного канала в продажах путём смены моделей атрибуции и сравнения одного показателя по каналу в разных атрибуциях сразу на одном графике.
Бизнес-терминал
Продолжить с готовой задачей
Выберите сценарий и при необходимости уточните вводные.
Что ещё почитать в блоге
Андата: как превратить данные в управляемый рост, а не в ещё один дашборд
У большинства компаний проблема не в том, что они плохо считают. Проблема в том, что между цифрами и реальными действиями остаётся ручной разрыв. Андата AI строится как система, которая помогает замыкать этот разрыв.
05.03.2026Почему ваша сквозная аналитика не приносит денег? 3 ошибки, которые убивают окупаемость рекламы в Яндекс.Директ
Вы внедрили сквозную аналитику, дашборды выглядят убедительно, но прибыль не растет.
05.02.2026Каннибализация в партнерке: почему пересечение с прямыми заходами еще ничего не доказывает.
Почти все конфликты вокруг партнеров начинаются одинаково: партнерскую регистрацию читают как источник трафика.
02.02.2026Когортный анализ маркетинговых усилий — строим любые воронки с Андатой
Расскажем, как можно применять инструмент «Воронки» на практике и какие преимущества он предлагает для бизнеса.
08.08.2024