Как использовать Big Data в рекламе и digital-маркетинге

С какими большими данными вы уже работаете в performance-маркетинге
Как большие данные помогают работать с ремаркетингом
Содержание
Содержание
Рынок digital-рекламы постоянно растет. На сегодняшний день уже 55% рекламы транслируется в цифровых форматах, а около 72% всех маркетинговых бюджетов в мире так или иначе относятся к digital-каналам (источник).
Одни компании запускают только поисковую рекламу, кто-то тестирует и другие контекстные инструменты, а некоторые активно используют еще и таргетированную, а также другие виды цифровой рекламы. И все это приводит к логичному результату — рекламодатель получает большое количество различных данных.
Но давайте на секунду переключимся от трендов и взглянем на то, что подразумевается под Big Data, или Большими данными. Множество определений можно “свернуть” в довольно простую формулировку:
Большие данные — это такие данные, которые соответствуют трем основным критериям (их еще называют “3 V”):
Объем (Volume) — этих данных действительно много.
Скорость (Velocity) — мы можем быстро получать их и обрабатывать.
Разнообразие (Variety) — мы собираем данные разных типов; они имеют различное смысловое наполнение.
И уже на данном этапе мы подходим к очень простой и важной мысли: получается, что каждый digital-маркетолог ежедневно генерирует, обрабатывает и анализирует большие данные. Как этот процесс выглядит в очень общем виде на примере запуска контекстной рекламы:
- Мы настраиваем определенные кампании, которые взаимодействуют с тысячами других кампаний в рамках общего аукциона: вся эта система – гигантский водоворот из больших данных;
- Кампании генерируют для нас большой объем статистики: по эффективности кампаний и ключевых фраз, по атрибутам аудитории, по поведению пользователей, перешедших на сайт, ставкам и т.д.;
- Мы строим из совокупности этих данных регулярные и ad-hoc отчеты, а также дашборды;
- На финальном этапе мы делаем определенные выводы, вносим какие-то изменения в рекламу — и весь цикл повторяется.
Отметим, что именно такой анализ и формирование выводов на основе больших данных в противовес принятию решений с упором на логику, ощущения или интуицию — это и есть Data-driven подход, основанный на принятии решение на основе данных.
Итак, большие данные — это не всегда что-то очень сложное уровня Data Science. Мы, того не замечая, работаем с ними каждый день, и именно они — наш лучший друг и проводник в мире, где все действия маркетолога должны быть взвешенными и обоснованными с помощью цифр.
Но это не говорит о том, что углубить работу с большими данными нельзя: для принятия еще более эффективных и быстрых решений мы можем доверить обработку big data искусственному интеллекту, построить на их базе Machine Learning системы, проектировать нейросети и использовать полностью автоматические системы управления рекламой.
Именно так и работает Андата — сервис управления рекламой на основе машинного обучения. Андата оперирует большими данными, которые обрабатываются обученной ML-моделью. Так мы рассчитываем лучшие ставки для вашей рекламы.
Рассмотрим примеры того, как digital-маркетологи используют большие данные в рекламе и как эти данные помогают нам настраивать эффективные рекламные кампании.
С какими большими данными вы уже работаете в performance-маркетинге
Сбор семантического ядра и прогноз бюджетов
Еще до запуска кампаний маркетолог уже постоянно касается различных больших данных. В первую очередь это заметно на этапе сбора семантического ядра: мы отдаем в рекламные системы список шаблонизированных поисковых запросов, которые может использовать наша целевая аудитория, а взамен за пару секунд получаем реальные ключевые фразы, которые обогащены дополнительной полезной информацией:
- помимо непосредственно вложенных запросов мы также получаем данные о синонимах, околотематических запросах, запросах с ошибками в написании и т.д.;
- вместе с запросами и данными о частотностях мы можем использовать усредненные данные о стоимости клика, конкуренции и другие метрики для более точной группировки семантического ядра и для прогнозирования бюджетов.
После выгрузки ядра его нужно очистить и кластеризовать — и это тоже работа с большими данными, которую можно делать как вручную, так и с помощью специализированных инструментов (KeyCollector, KeyAssort и другие).
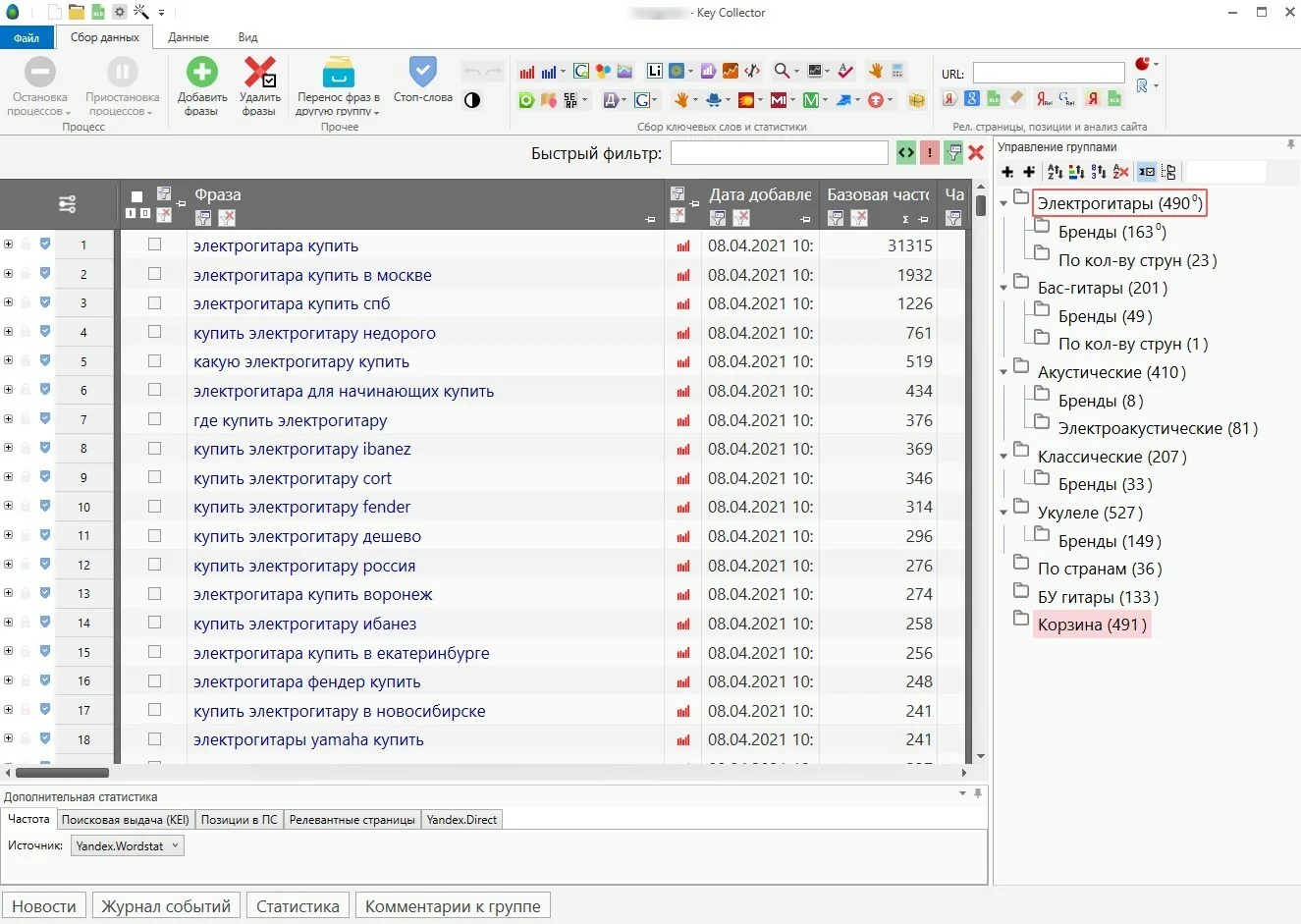
KeyCollector – инструмент для сбора и кластеризации семантического ядра
Важной особенностью работы с большими объемами семантики является то, что на сегодняшний день львиная доля процессов поддается автоматизации — это позволяет формировать огромные и неплохие по качеству проработки семантические ядра за считанные часы.
Показ рекламы, аукционы и применение автоматических стратегий
После сбора и кластеризации семантического ядра мы формируем группы объявлений и сами объявления — а далее начинаем транслировать нашу рекламу. Но мало кто из маркетологов задумывается о работе big data внутри рекламных систем в условиях постоянного функционирования аукциона.
Сейчас мы не будем углубляться в технические особенности аукционов на поиске, в РСЯ / GDN, площадках RTB, но давайте задумаемся: площадки в ответ на поисковый запрос или какое-то действие пользователя мгновенно обрабатывают текущий статус аукциона и, в соответствии с алгоритмами, подбирают рекламодателей и объявления для показа. И этот процесс происходит ежесекундно на тысячах площадок. Что это если не большие, очень большие данные, которых вы касаетесь ежедневно, запуская digital-рекламу?
Внешний вид рекламных объявлений
Но рекламные системы на основе больших данных выбирают не только, когда показывать объявление, но и как его показывать. Сегодня они на основе множества сигналов подбирают как формат объявления, так и конкретное сочетание элементов (заголовки, описания, расширения) под конкретного пользователя с целью повышения вероятности клика и конверсии.
Это также происходит в реальном времени на основе ML-алгоритмов и совершенно незаметно как для пользователя, так и для рекламодателя.
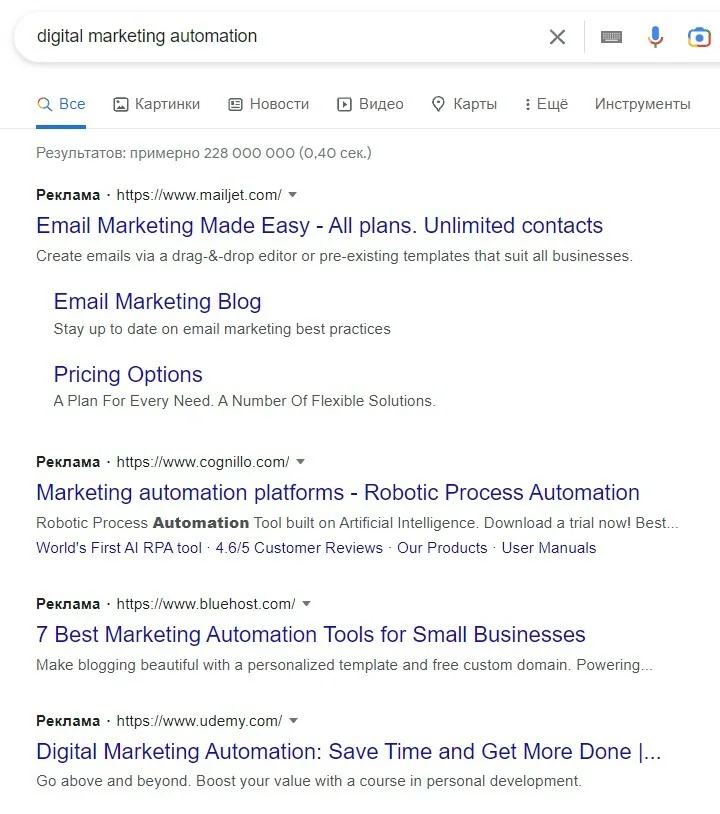
На скриншоте видно, как отличается отображение объявлений от 4-х разных рекламодателей:
- 2 заголовка, 1 описание, 2 дополнительных ссылки с описаниями
- 2 заголовка, 1 описание, 4 дополнительных ссылки без описаний
- 1 заголовок, 1 описание
- 1 заголовок, 1 описание
Обмен конверсиями между веб-аналитикой, CRM и рекламными кабинетами
Вспомним и об автоматических стратегиях в контекстной рекламе. Это еще более сложная система, где происходит постоянный обмен большими данными между вашим сайтом, веб-аналитическими инструментами и рекламными системами. На основе ваших данных рекламная система в ответ на запрос или поведение пользователя в реальном времени оценивает вероятность конверсии и на основе этого принимает решение о показе рекламы.
В схему можно добавить и еще один источник данных — CRM. Таким образом, вы можете связать рекламу не только с данными о каких-то целевых действиях, но и сделать детализацию по текущему статусу конкретного лида, передавать данные об оффлайн-конверсиях, добавить к аналитике детализацию по менеджерам отдела продаж и т.д.
Все это ни что иное, как big data, которая помогает нам в ручном и автоматическом режиме оптимизировать рекламу и повышать качество входящего трафика.
Big Data и медийная реклама
Но большие данные помогают увеличить эффективность не только performance-рекламы, но и серьезно облегчают продвижение бренда через медийные инструменты.
Анализ портрета целевого клиента
Имея в своем распоряжении большие данные, маркетолог может проанализировать различные характеристики посетителей сайта: социально-демографические, поведенческие, географию пользователей, используемые устройства и прочее.
В результате мы можем построить портрет идеального клиента — после чего запустить медийную рекламу на пользователей со схожими характеристиками, но только на тех, кто еще не знаком с нашим продуктом и веб-сайтом. Это хоть и долгосрочный, но эффективный способ формирования спроса и улучшения осведомленности о бренде среди потенциальной целевой аудитории.
Look-alike
У вас накопилось много данных о ваших клиентах, например их телефоны и электронные почты? Соедините эту информацию с большими данными из рекламных систем — и алгоритмы помогут найти похожих пользователей! Работает это очень просто:
- Мы каким-то образом показываем рекламным системам сегмент аудитории, который для нас является сверхцелевым: это может быть уже упомянутая загрузка данных клиентов, выделение сегментов пользователей с конверсиями или определенными характеристиками в веб-аналитике и т.д.
- Вы выбираете целевой процент схожести выбранной сверхцелевой аудитории и новой, после чего рекламная система находит похожих пользователей – и показывает им вашу рекламу. Обычно в подобных рекламных кампаниях исключают показ на пользователей, которые уже посещали ваш сайт или совершали покупки.
Показ рекламы рядом с релевантным контентом
Данное решение может быть как отличным медийным, так и неплохим performance-инструментом. Идея заключается в том, что мы можем показывать свою рекламу рядом с релевантным контентом.
Рекламные системы в реальном времени анализируют большие данные о настройках ваших кампаний, контент сайта и объявлений, сопоставляют его с доступными местами показа — и показывают объявление там, где это уместно по смыслу.
Только представьте, насколько потенциально может вырасти эффективность рекламы агрегатора авиабилетов, если показывать ее внутри статьи о путешествиях или рекламы спортивного питания, если она показывается на сайте с тренировочными схемами.
Affinity-индекс
Если не углубляться в сложные определения и методики подсчета, то скажем, что affinity-индекс — это рассчитанный на больших данных индикатор того, насколько ваша целевая аудитория схожа с какой-то другой аудиторией на рынке. Чем он выше, тем выше схожесть двух анализируемых аудиторий.
Если упростить еще больше, то affinity-индекс показывает, какие интересы характерны для аудитории нашего сайта. И на основе этих данных можно настраивать медийные кампания для поиска новых потенциальных клиентов.
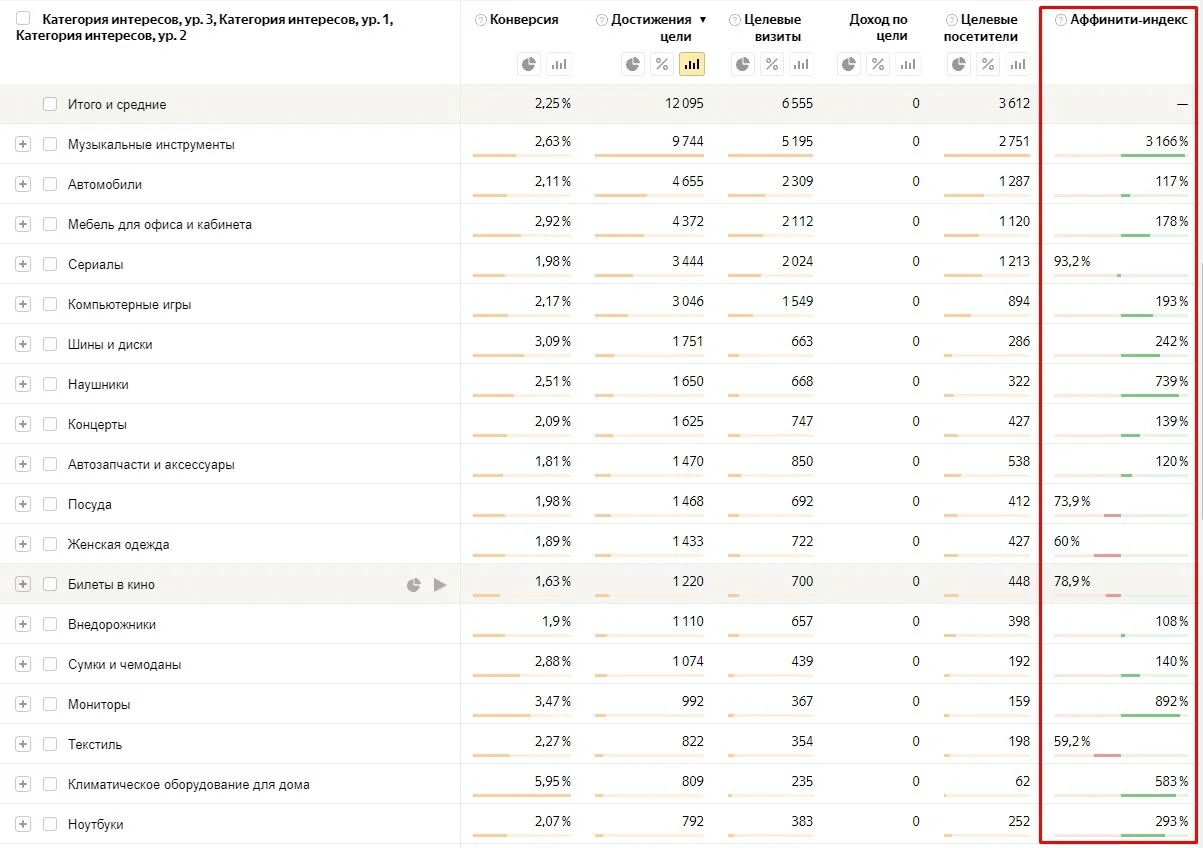
Например, на данном скриншоте мы добавили к отчету “Долгосрочные интересы” в Яндекс Метрике данные по достижению цели “Покупка” — и на основании полученных данных по affinity-индексу мы вполне можем сделать выводы о смежных интересах нашей целевой аудитории.
DMP-сегменты
Данные сегменты пользователей собирают DMP-площадки (Data Management Platform), после чего эти сегменты, конечно-же с согласия попавших них пользователей, группируются по различным критериям (интересы, характеристики и др.) и становятся доступны для рекламного таргетинга на отдельных рекламных площадках.
Таргетинг на DMP-сегменты — хороший способ поиска целевой аудитории среди внешних больших данных, который абсолютно легален, прост с точки зрения настройки, но может быть очень эффективен в случае настройки грамотных цепочек ремаркетинга.
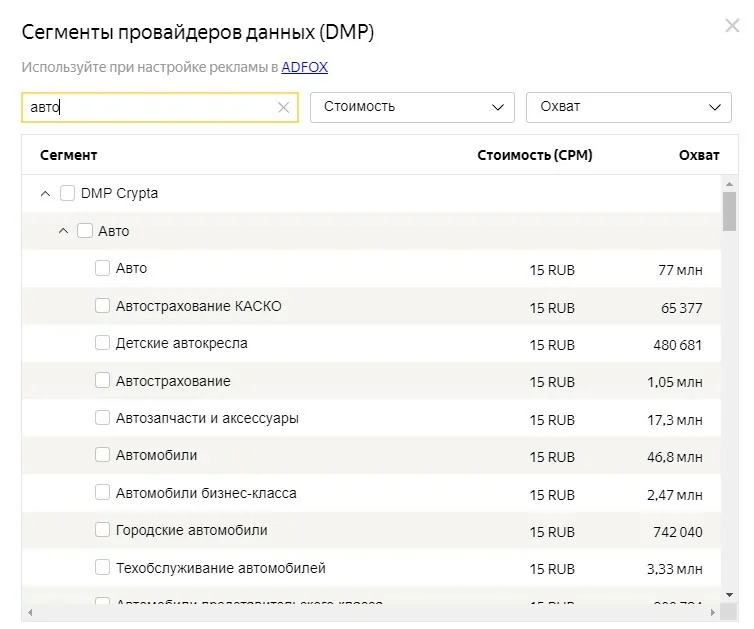
Пример DMP-сегментов из автомобильной тематики с указанием охвата и CPM
Как большие данные помогают работать с ремаркетингом?
Зачастую коэффициент конверсии по тем пользователям, которые уже посещали ваш сайт, но еще не совершили покупку, может быть выше, чем по новым посетителям. Почему бы не попробовать вернуть часть пользователей на наш сайт, чтобы замотивировать их все-таки совершить покупку или оставить лид на сайте?
Классический ремаркетинг
С помощью больших данных, которые аккумулируют для вас инструменты веб-аналитики и рекламные пиксели, вы можете отобрать потенциально «лучшую» часть пользователей, уже посетивших ваш сайт. После этого мы можем исключить из нее тех, кто уже совершил конверсию — и старгетировать рекламу на остальных!
Каскадный ремаркетинг
Некоторые продукты (например, дорогие товары с длинным циклом сделки) подразумевают длительную цепочку «прогревания». Конкретный пользователь в таких случаях может посещать сайт перед покупкой, 3, 5 или более раз! И для ремаркетинга здесь может требоваться уже более сложная цепь условий включения и исключения из аудитории, а также многоступенчатая система знакомства пользователя с нашим оффером.
Однако принцип остается тем же: мы пользуемся теми данными, которые нам дают рекламные кабинеты и инструменты веб-аналитики, чтобы находить наилучшие сегменты аудитории.
Прогнозные модели от Google Analytics
Еще одним из примеров работы с ремаркетингом является прогноз конверсии в Google Analytics. Здесь большие данные используются уже не только для ручного анализа: инструмент самостоятельно строит ML-алгоритм, который разделяет некоторых посетителей вашего сайта на сегменты с указанием вероятности конверсии.
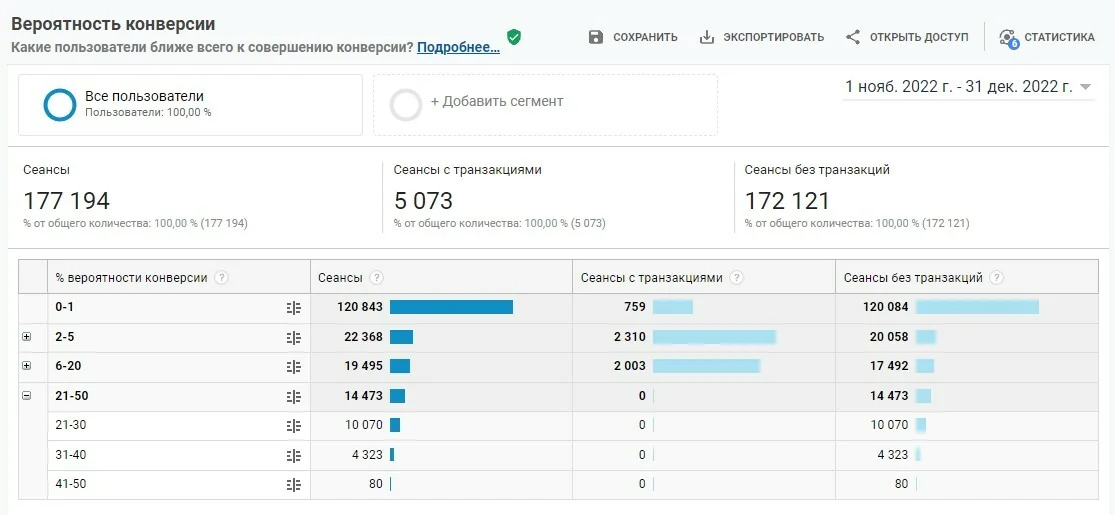
Вишенкой на торте является то, что мы можем настроить ремаркетинговые кампании на сегменты с высокой прогнозной конверсией, исключив из них тех, кто уже достиг конверсии.
Дополнительные продажи и персонализация рекламы через загрузку аудиторий клиентов
Выше мы уже писали, что вы можете загружать базы клиентов в рекламные системы, чтобы искать похожих пользователей. Но никто не мешает настроить рекламу и напрямую на аудиторию клиентов для получения дополнительных продаж или формирования для них персонализированных офферов: скидок, предложения дополнительных товаров и др.
Аналитика больших данных
Итак, мы надеемся, что вы уже на 100% убедились в том, что big data в современном маркетинге — это не что-то уникальное, страшное и сложное. И в том, что маркетологи так или иначе работают с большими данными в рекламе каждый день.
И как вы уже могли заметить, большие данные регулярно используют и для различной аналитики: маркетинговой, рекламной, продуктовой и др.
Наиболее популярным вариантом сбора и аналитики больших данных в современных компаниях является подключение бесплатных сервисов от крупных рекламных провайдеров: Google Analytics и Яндекс Метрика. Это наиболее простой, но эффективный вариант сбора больших данных без существенных затрат, однако у него есть очевидные недостатки: человеческий фактор, неполнота данных (чем крупнее проект — тем менее полными и корректными будут данные), отсутствие возможностей глубокой автоматизации и кастомизации.
Альтернативой такой реализации сбора больших данных является подключение различных «коробочных» внешних сервисов, которые могут дополнять или даже полностью заменять бесплатные варианты. Среди самых популярных типов таких сервисов можно выделить инструменты сквозной аналитики, а также инструменты автоматизации управления рекламой. Из недостатков: эти инструменты платные.
Из очевидных преимуществ:
- Эти инструменты не просто собирают данные, они способны их интерпретировать, строить сложные ML-модели;
- Подключение большинства инструментов управления рекламой сводится к простому предоставлению доступа к рекламного аккаунту;
- Они дают больше возможностей кастомизации, автоматизации и визуализации данных;
- AI делает выводы и принимает решения на основе сырых данных эффективнее и быстрее, чем человек;
- Зачастую они проще в использовании, чем комплексные инструменты, вроде Analytics или Метрики;
- Вы всегда можете попросить помощи у технических специалистов на стороне сервиса.
Какой из вариантов более эффективен для конкретной компании — вопрос индивидуальный. Мы уже готовим серию материалов по этой теме.
Выводы
Большие данные в цифровом маркетинге используются повсеместно: они генерируются рекламными системами, используются ими же для более точного таргетинга.
Анализ больших данных помогает рекламодателям лучше понять свою целевую аудиторию и более точно найти ее, индивидуализировать рекламу и делать кастомизированные предложения своим клиентам.
Чтобы работать с большими данными нужны автоматизированные системы. Такие системы строятся на алгоритмах машинного обучения, что позволяет обрабатывать big data быстро и точно, находить закономерности в данных и получать полезные инсайты.
Часто ищут в Андате
Бледным отмечены запросы, для которых на сайте пока нет готового материала.
big data данные
использование big data
кластеризация семантического ядра
семантическое ядро
- семантическое ядро сайта
- как собрать семантическое ядро
- сбор семантического ядра
- семантическое ядро слово
что такое big data
- анализ big data
- big data вопросы
- обработка big data
- анализ данных big data
обработка данных big data
- big data работа
- c big data
- технология big data большие данные
- big data объем
1 big data
- управление big data
- характеристика big data
- к big data относятся
- методы big data
big data объем данных
- big data dangerous
- обработка больших данных big data
- big data информация
- использование больших данных big data
семантическое ядро онлайн
- семантическое ядро запроса
- семантическое ядро яндекс
- сервиса семантического ядра
- семантическое ядро ключевые
анализ семантического ядра
- семантическое ядро seo
- семантическое ядро рекламы
- семантическое ядро страницы
- семантическое ядро директа
пример семантического ядра
- семантическое ядро конкурента
- семантическое ядро ключевых слов
- составление семантического ядра
- бесплатное семантическое ядро
структура семантическое ядро
- как составить семантическое ядро
- семантическое ядро яндекс директ
- правильное семантическое ядро
- семантическое ядро сайта онлайн
подбор семантическое ядро
- семантическое ядро страницы сайта
- семантическое ядро текста
- семантическое ядро контекстная
big data в рекламе
Новые материалы — на почту
Подписаться на блог Андаты
Отправляем только редакционно одобренные статьи, обучение и обновления платформы. Старый архив не рассылаем как новый.
Подписка активируется только после подтверждения адреса в письме.